Idea tej części programu polega na policzeniu prędkości spalania kinetycznego dla różnych współczynników stechiometrii. Działa to mniej więcej tak:
Ustaw współczynnik stechiometrii z listy
Policz prędkość spalania
Zapisz wyniki
Jeżeli jest dostępny to wróć do punktu 1 i ustaw nowy współczynnik stechiometrii. W przeciwnym razie:
Wyświetl wyniki dla każdego przypadku na wykresie.
To nie są iteracje, to są kolejne, osobne przypadki. Właśnie te 9 przypadków chciałbym rozwiązywać możliwie równolegle. Np ograniczyć się do 8 przypadków i robić 2x4 przypadki na czterordzeniowym procesorze.
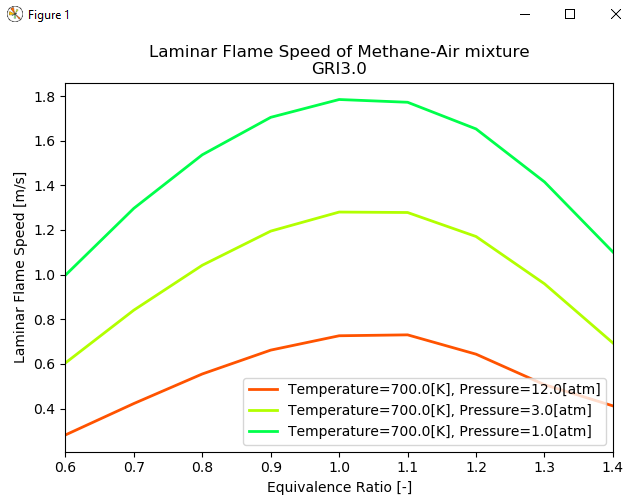
Tak wygląda wynik programu, który uwzględnia trzykrotne uruchomienie pętli for dla różnych ciśnień:
EDIT:
Czy ja dobrze rozumiem, że powinienem zawrzeć wszystko w pojedynczej funkcji “def funckja(parametr)” i wywoływać je równolegle dla różnych inputów?
Zakładam, że każdy taki przypadek jest dość kosztowny obliczeniowo (czyt. długo się liczy). Swego czasu używałem wielowątkowości w C na MS Windows i podszedłbym do tego tak, że odpaliłbym 9 wątków i do każdego przekazał inny zestaw danych wejściowych (czyli te niekolidujące z innymi dane). Taki wątek to w dużym uproszczeniu podprogram/procedura/funkcja. Wygląda na to, że w Twoim przypadku taką daną jest współczynnik stechiometrii, zaś funkcja licząca jest zawsze ta sama (tj. algorytm jest stały). W C przydatny był jeszcze jakiś mechanizm synchronizacji wątków (zdarzenia, semafory, muteksy, sekcje krytyczne), bym wiedział, kiedy zakończyły pracę i np. można zebrać/wyświetlić dane. Ważne - nie sugeruj się liczbą rdzeni CPU, bo w każdym OSie jest tzw. planista, który przydziela czas CPU do poszczególnych zadań. Jeśli masz jednowątkowe zadanie to ono rzadziej dostanie CPU niż wielowątkowe (w nowoczesnych OSach przydział zadań jest na poziomie wątków/procesów). Nie można tylko przegiąć w drugą stronę - jeśli w OSie już działa dużo wątków/procesów to dołożenie zbyt dużej ich liczby od siebie zwyczajnie zamuli CPU (planista więcej czasu będzie spędzał na przełączaniu zadań CPU niż CPU na samym ich wykonywaniu).
Każda jedna pętla for liczy się około 5 minut (nie jest to bardzo długo) ale ponieważ celem jest optymalizacja, przewiduję policzenie przynajmniej 1000 przypadków co staje się dość uciążliwe czasowo. Przejście na język C nie wchodzi w grę ze względu na to, że biblioteki do programu Cantera są dostępne w języku Python i dodatkowo wiele moich kodów również jest w tym języku.
Jest tak jak mówisz, współczynnik stechiometrii jest jedynym parametrem zmiennym dla poszczególnych iteracji.
Ilość wątków dobrałbym eksperymentalnie, żeby wykorzystać możliwie dużo mocy obliczeniowej.
Tak na prawdę temat wydaje mi się wciąż otwarty, nie do końca wiem jak powinienem do tego podejść w Python.
Wydaje mi się, że domyślna implementacja Pythona jest monowątkowa. Można tworzyć wątki, ale w ten sposób zrównoleglone zostają tylko wywołania bibliotek zewnętrznych w C, albo operacje IO.
Zrównoleglenie znane z innych języków można uzyskać poprzez tworzenie oddzielnych procesów. Komunikacja między procesami jest dość wolna, ale jeśli jedno wywołanie pętli trwa 5 minut, to ma to jak najbardziej sens.
Tutaj jest pokazane jak można zrobić pulę procesów, a następnie przesyłać do niej zadania: https://docs.python.org/3/library/multiprocessing.html
Podsumowując: Jeśli korzystasz z zewnętrznej biblioteki spróbuj wywołać pętlę na wątkach i przy uruchomieniu programu zobacz jakie jest użycie procesora. Jeśli jest bliskie 100%, to jest git, a jeśli jest dużo niższe spróbuj wywołać pętlę w oddzielnych procesach.
Zgadza się (dla mnie to dość dziwne, ale cóż - widać taki urok Pythona). Źródło:
It’s tempting to think of threading as having two (or more) different processors running on your program, each one doing an independent task at the same time. That’s almost right. The threads may be running on different processors, but they will only be running one at a time.
Getting multiple tasks running simultaneously requires a non-standard implementation of Python, writing some of your code in a different language, or using multiprocessing which comes with some extra overhead.
Nie jestem pewien czy dobrze rozumiem. Jak wywołam program prosto z cmd poprzez “py nazwa.py” to z użycie procesora dla python.exe wynosi te 25 procent czyli jeden z czterech rdzeni.
Obecnie zawarłem całą swoją funkcję w definicji i można ją wywłoać powiedzmy tak:
from __future__ import print_function
import cantera as ct
import numpy as np
import matplotlib.pyplot as plt
def lamiarFlameSpeed (gas,phi):
[celowo pominiete bo bez znaczenia]
return f.u[0]
gas = ct.Solution('gri30.cti')
gas.TPX = 298, 101325, 'CH4:1'
gas()
phi=1
gas1 = ct.Solution('gri30.cti')
gas1.TPX = 298, 101325, 'CH4:1'
gas1()
phi1=1.1
gas2 = ct.Solution('gri30.cti')
gas2.TPX = 298, 101325, 'CH4:1'
gas2()
phi2=1.2
print('\nMixture-averaged flamespeed at phi = {:1.1f} is {:7f} m/s'.format(phi,lamiarFlameSpeed(gas,phi)))
print('\nMixture-averaged flamespeed at phi = {:1.1f} is {:7f} m/s'.format(phi1,lamiarFlameSpeed(gas1,phi1)))
print('\nMixture-averaged flamespeed at phi = {:1.1f} is {:7f} m/s'.format(phi2,lamiarFlameSpeed(gas2,phi2)))
i tak dalej.
Jak dla mnie pierwszy krok to określenie danych wejściowych. Może to być lista tupli obiektów gas i phi, a jeśli te obiekty są podobne, to można je wygenerować taką pętlą for jak w pierwszym kodzie, który zamieściłeś.
Drugi krok, to określenie jak te dane mają zostać przeliczone. Tutaj zakładam, że to jest funkcja lamiarFlameSpeed.
Trzeci krok, to określenie co ma się stać z wynikiem obliczeń.
Mając drugi krok można łatwo użyć multiprocessingu (pseudokod zgodnie z dokumentacją pythona):
from multiprocessing import Pool
input = [(gas, phi), (gas1, phi1), ......]
with Pool(4) as p:
result = p.starmap(lamiarFlameSpeed, input)
twierdzi, że gas1 i gas2 jest not pickable. “Solution object is not picklable”. Zdaje się więc, że jest to ślepy zaułek.
Wkrótce dam znać jak poradziłem sobie z Pool
Dzięki wielkie!
EDIT:
Niestety ten sam problem. gas jest obiektem typu Soltuion. Chyba nie da się go użyć jako argument.
Spróbuję wyciągnąć dane na zewnątrz funkcji laminarFlameSpeed i definiować gas w środku.
Pool jest o tyle fajne, że potrafi zkolejkować zadania i wykonywać je po kolei na określonej liczbie procesów. Stworzenie procesu dla każdego przypadku może spowodować, że tych procesów będzie dużo i wydajność spadnie mimo wysokiego obciążenia procesora, bo duża część mocy pójdzie na obsługę context switchingu itd.
[...]
from multiprocessing import Pool, freeze_support
def laminarFlameSpeed (mech,temp,press,fuel,phi):
[...]
input = [(mech,298,101325,'CH4:1',1),(mech,398,101325,'CH4:1',1)]
if __name__ == '__main__':
freeze_support()
with Pool(2) as p:
result = p.starmap(laminarFlameSpeed, input)
Wyniki dla dwóch przypadków dostałem w ciągu 2 sekund podczas gdy na całość trzeba czekać około 20 sekund.
Dzięki temu będę mógł liczyć więcej przypadków na raz! Dziękuje!
EDIT2:
Nie jestem jednak pewien tego rozwiązania bo python.exe wciąż ma 25%
Wg mnie it’s perfectly normal. Rozwiązanie działa, bo zaobserwowałeś zysk na czasie obliczeń. Na wątkach zyskał byś jeszcze odrobinę więcej, bo koszt/czas przełączania kontekstu wątku < analogicznego przełączania procesu.
Nie napisałem, że zaobserwowałem zysk. Po prostu czas pomiędzy uzyskaniem wyniku dla pierwszego przypadku i drugiego przypadku był bardzo krótki. Nie sprawdziłem czy całość trwała krócej. Pewne jest, że wykonywały się one w tym samym czasie jednak po zaobserwowanym zużyciu procesora nie mogę potwierdzić zysku.
Aby to określić dodam sobie funkcję liczącą czas i sprawdzę rzeczywisty czas całej operacji.
Serial:
Zwykłe wykonanie funkcji jedna po drugiej.
Pool:
if __name__ == '__main__':
freeze_support()
with Pool(5) as p:
tab_vel.append(laminarFlameSpeed(mech,298,101325,'CH4:1',1))
tab_vel.append(laminarFlameSpeed(mech,298,101325,'CH4:1',1.2))
Jedyne, które wykonuje obydwie funkcje na raz.
Thread:
if __name__ == '__main__':
Thread(target = laminarFlameSpeed1).start()
Thread(target = laminarFlameSpeed11).start()
Niestety zawsze czas obliczeń jest zbliżony a zużycie procesora wynosi 25%.
Skoro monowątkowy program obciąża jeden rdzeń na 100%, to zrównoleglony program (o ile ma wystarczającą ilość danych wejściowych oraz nie ma blokad wątków w kodzie) powinien generować obciążenie całego CPU bliskie 100%.
Nie rozumie tego fragmentu kodu. Pula procesów nie jest tutaj użyta, więc ten program wykonuje się tak jak w przypadku Serial.
Co do samego Pool to można go stworzyć bez argumentów, wtedy ilość procesów będzie równa ilości corów procesora.
No przy takim kodzie sprawa jest bardziej skomplikowana.
Tak, jest to związane z ilością procesów. Każdy proces wczytuje Twój kod oddzielnie, dlatego czas pojawił się 4 razy.
Cały kod odpalasz w funkcji main, ale mierzenie czasu masz zrobione poza funkcją w przestrzeni globalnej. Tak na prawdę mierzysz czas w jakim interpreter pythona załadował definicję funkcji main, a nie czas jej wykonania.
if __name__ == '__main__':
start = time.time()
freeze_support()
with Pool() as p:
p.starmap(laminarFlameSpeed,input)
end=time.time()
print(end-start)
w wyniku dostaję już tylko:
Mixture-averaged flamespeed at phi = 1.0 is 0.606019 m/s
Mixture-averaged flamespeed at phi = 1.0 is 0.375955 m/s
25.332786321640015
Także ten temat został rozwiązany. Być będę musiał jeszcze zasięgnąć waszej pomocy w niedalekiej przyszłości - na razie mam tylko bazę programu, muszę napisać jeszcze cały kod optymalizujący.
Tymczasem dziękuję Ci bardzo za Twój czas, opłaciło się!