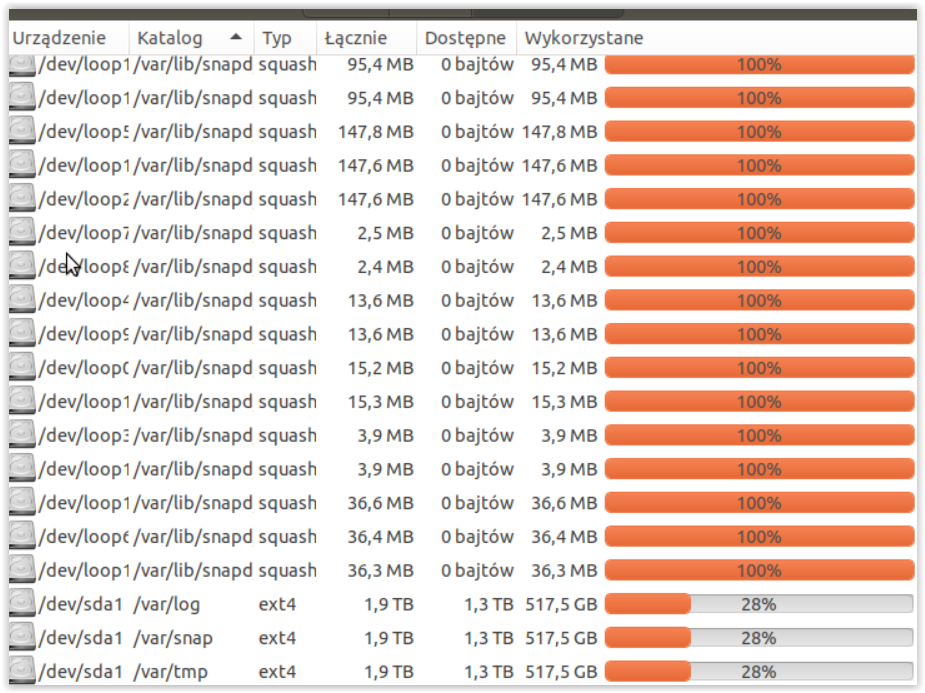
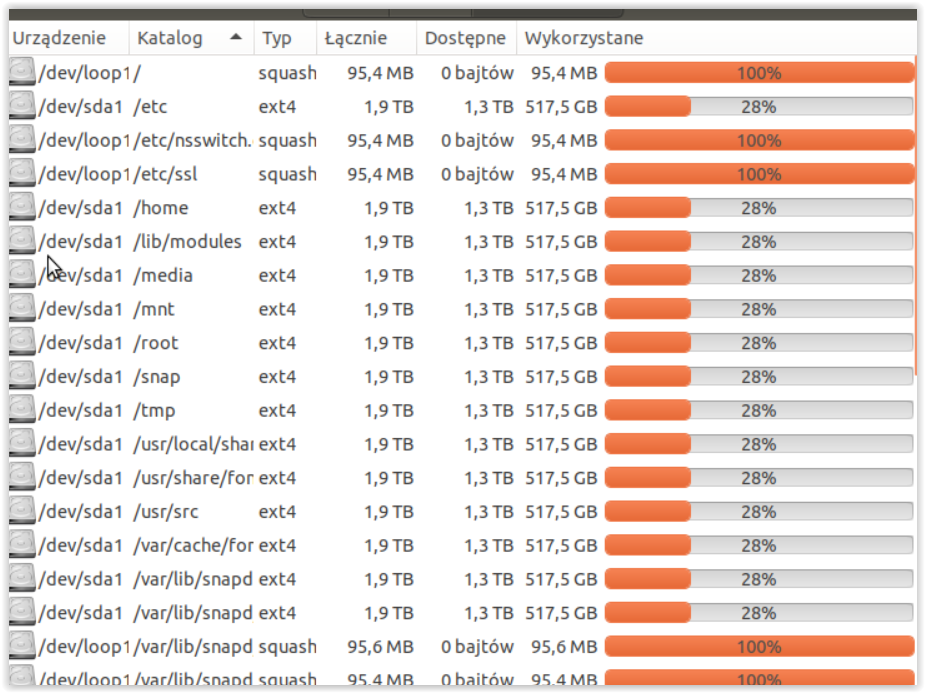
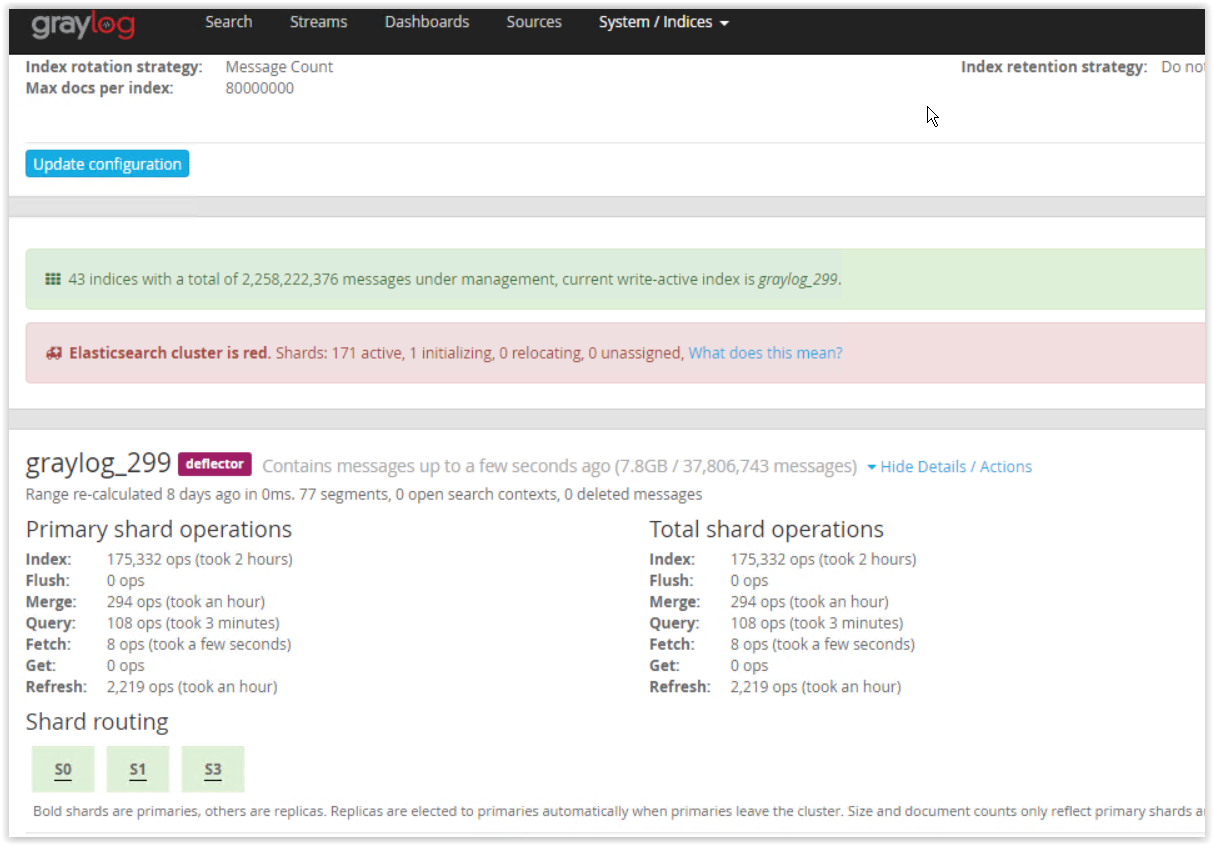
Hej, mam greyloga od jakiś 2 miesiący nie było problemu, procek 4 rdzeniowy, 8gb ram (Wszystko zużywane na jakieś 80%) , logi nie nadpisują się po prostu chcę zapisywać wszystko, paczki robią się po 15 GB , aktualnie mam jakieś 150GB zajętości ,
Od kilku dni zaczął świrować procesor skoczył na 100%, nie mogę przeglądać logów, zawiesza się przeglądarka, niby coś tam loguje (mam 4 węzły) ale nie jest to tyle ile było wczesniej dziwnie ten ruch idzie…
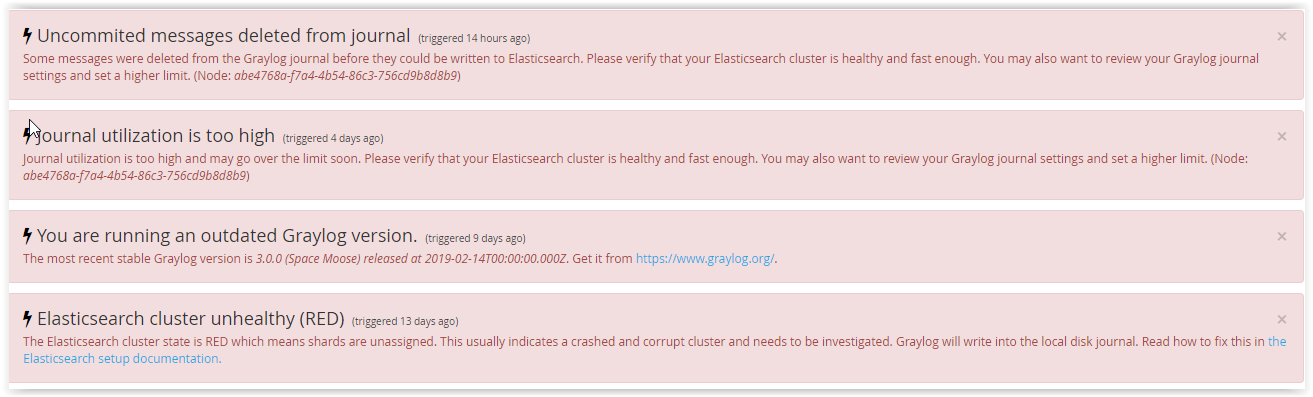
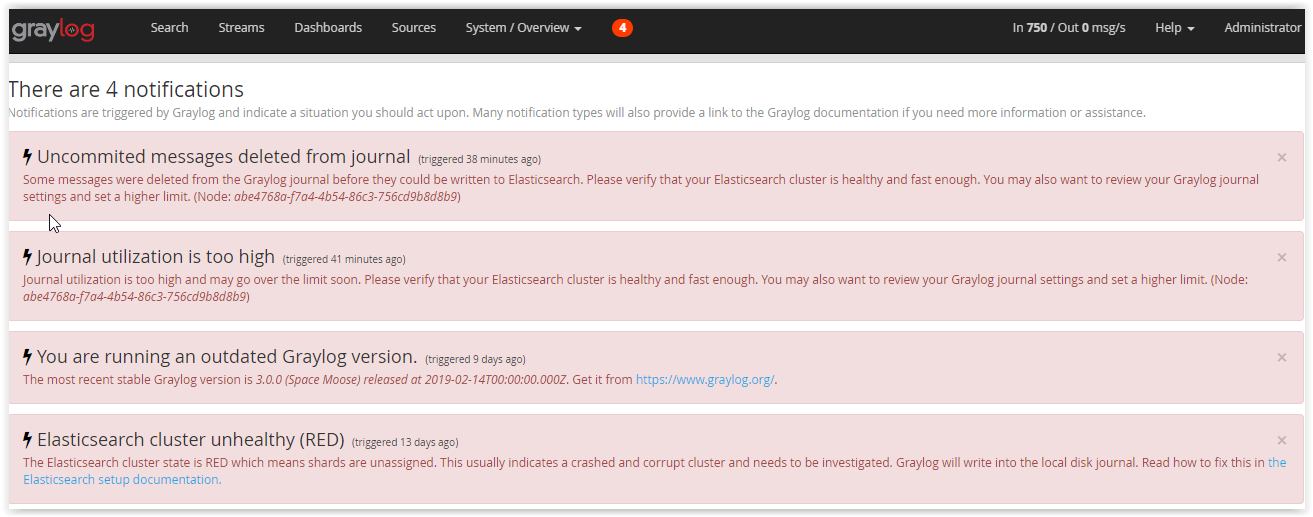
sypie takimi komunikatami :
Co mu się stało i dlaczego? czyżby przerosło go to że 150GB danych ma zebranych? ja chciałem na nim 2TB zbierać… jak go ożywić żeby nie stracić też tego co zapisal
Snapd to daemon obsługujący paczki snap. Snapy to takie kontenerki z aplikacjami - takie biedne rozwiązanie “problemów” instalacji programów na Linuksie - Canonical próbuje na wzór Windowsa zepsuć to, co ktoś wymyślił ponad 20 lat temu - współdzielenie biblioteki.
Masz jeszcze jakieś pomysły co się może dziać z elasticem że tak się zachowuje?
takimi błedami ładuje graylog
RemoteTransportException[[Star-Dancer][127.0.0.1:9300][indices:data/write/bulk[s]]]; nested:
UnavailableShardsException[[graylog_299][1] primary shard is not active Timeout: [1m], request:
[BulkShardRequest to [graylog_299] containing [129] requests]];
Zamontowałem w nim dysk 2 TB (ogolnie to stoi na proxmox) i usunąłem opcje nadpisywania chciałem żeby mi zapisywał wszystko w paczkach po 15GB aż dojdzie do tych 2TB, a on się przy jakiś 500GB zawiesił bo ma za dużo ? dobrze to rozumiem ?
Wygoglowałem że komunikat OutOfMemoryError[Java heap space] ; oznacza przepelniona Java , domyślnie ma ustawione 1gb , pytanie gdzie to zmienić na wiecej ?
Miałeś kiedyś taki przypadek? domyślnie piszą że w /etc/elasticsearch powinienem znaleźć plik konfiguracyjny Java, u mnie nie ma takiego pliku, znalazłem takie coś w init.d i ustawiłem
ES_HEAP_SIZE="-Xms2G -Xmx2G" oraz to ES_JAVA_OPTS="-Xms2G -Xmx2G" ./bin/elasticsearch
I went in init.d and set it up
PATH=/bin:/usr/bin:/sbin:/usr/sbin
NAME=elasticsearch
DESC="Elasticsearch Server"
DEFAULT=/etc/default/$NAME
if [ `id -u` -ne 0 ]; then
echo "You need root privileges to run this script"
exit 1
fi
. /lib/lsb/init-functions
if [ -r /etc/default/rcS ]; then
. /etc/default/rcS
fi
# The following variables can be overwritten in $DEFAULT
# Run Elasticsearch as this user ID and group ID
ES_USER=elasticsearch
ES_GROUP=elasticsearch
# Directory where the Elasticsearch binary distribution resides
ES_HOME=/usr/share/$NAME
# Heap size defaults to 256m min, 1g max
# Set ES_HEAP_SIZE to 50% of available RAM, but no more than 31g
ES_HEAP_SIZE="-Xms2G -Xmx2G"
# Heap new generation
#ES_HEAP_NEWSIZE=
# max direct memory
#ES_DIRECT_SIZE=
# Additional Java OPTS
ES_JAVA_OPTS="-Xms2G -Xmx2G" ./bin/elasticsearch
# Maximum number of open files
MAX_OPEN_FILES=65536
zaczęło to działać z tym że dalej pisze 1GB a powinno się chyba zmienić po tych ustawieniach na 2GB?
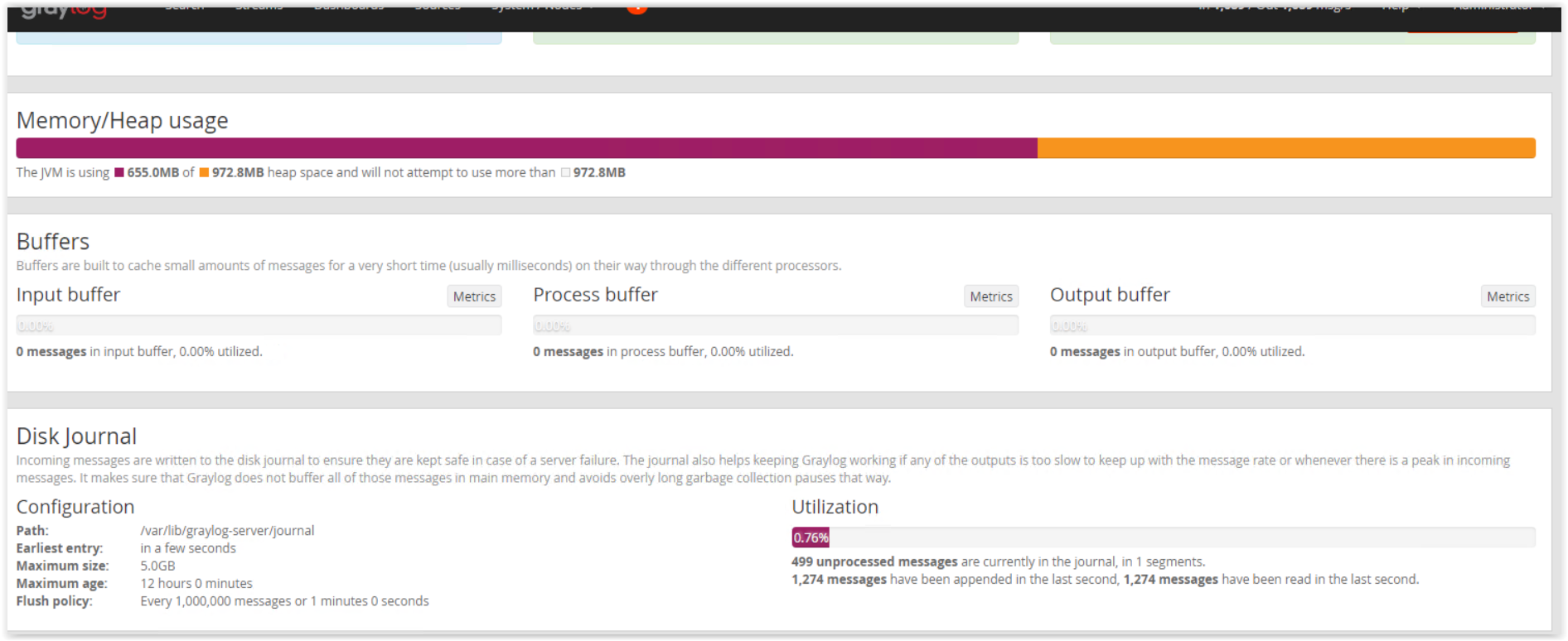
zastanawia mnie ten Process buffer i Output buffer jak były problemy to one były na 98-100% , a teraz jest 0%, dodatkowo spadło obciązenie procesora z 90% na 35% ramu żżre więcej około 11GB
Jak to wytłumaczyc ? to co zrobiłem pomogło czy jakiś zbieg okoliczności ?