Miałem potrzebę coś wyszukać w swoich postach na forum i pobrałem swoją zawartość. No i to by było na tyle. Rok temu było to czytelne, a teraz przykład:
Jeśli są jakieś różnice, to adresowane do konkretnych osób, bo inaczej cenią się osoby, które znają się i prędzej zaufają sobie. W odniesieniu do nieznanych sobie nicków, dużo trzeba wiary w ludzi, że nie nabrudzą na forum itp.
Zawartość nie jest utracona, tylko kodowanie jest … takie jakie jest.
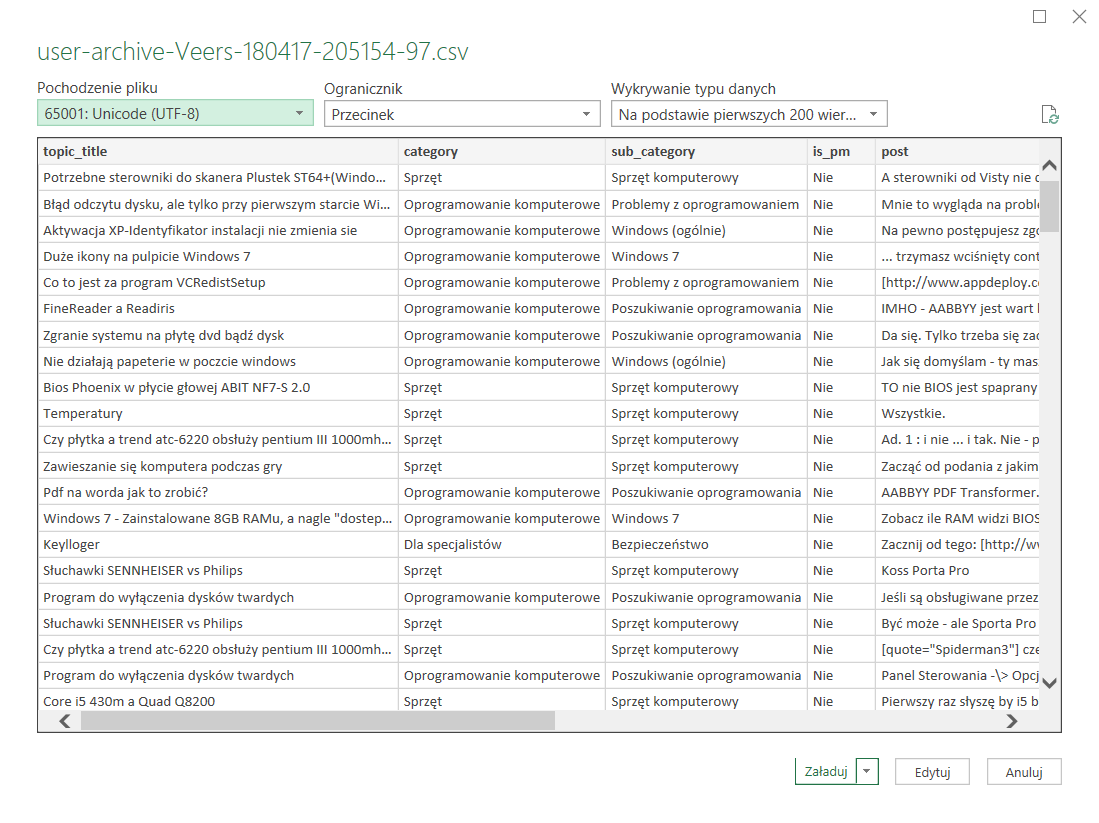
Użyj importu danych do Excela z pliku .csv , a jako kodowanie wybierz 65001: Unicode (UTF-8) a otrzymasz to, co ja na załączonym obrazku: